OpenCL vs CUDA:性能比拼,哪个更快?
在高性能计算的广阔领域中,cuda与opencl无疑是两颗璀璨的明星。它们都致力于通过并行计算技术,将gpu的强大计算能力引入通用计算领域,从而极大地提升计算效率和性能。然而,对于广大开发者而言,cuda和opencl哪个更快,一直是一个备受关注且充满争议的话题。本文将从多个维度对这两者进行全方位解析,旨在帮助读者更好地理解它们的差异,从而做出最适合自己需求的选择。
设计理念与平台支持

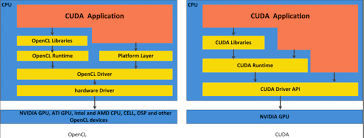
cuda,由nvidia公司开发,是一种特定于nvidia gpu的并行计算平台和编程模型。它使用c/c++语言进行编程,并允许开发者编写并行计算应用程序,直接访问gpu的硬件资源,如gpu内存、cuda核心等。因此,cuda在nvidia gpu上能够实现极高的性能。
相比之下,opencl则是一种跨平台的并行计算框架,由khronos group开发。它支持多种硬件平台,包括nvidia、amd、intel的gpu,以及cpu和fpga等。opencl使用c99语言作为基础,并引入了特定的api和内核语言来编写设备代码。这种跨平台性使得opencl在多种硬件设备上都能运行,但也可能导致在特定硬件上的性能优化不如cuda深入。
性能优化与生态系统
cuda在nvidia gpu上的性能优化无疑是其最大的优势之一。由于cuda是专为nvidia gpu设计的,因此它能够充分利用gpu的硬件特性进行深度优化,从而在nvidia硬件上提供更高的性能。此外,cuda还拥有庞大的生态系统和丰富的开发资源,包括开发者社区、工具链、sdk以及各类库(如cublas、cudnn等),这些都为开发者提供了极大的便利。
opencl则由于其跨平台性,在性能优化上可能不如cuda那么深入。然而,它也提供了一种通用的计算平台,能够支持多种处理器和设备。opencl的生态系统虽然相对分散,但不同厂商都提供了各自的opencl实现和工具,因此开发者仍然可以在多种硬件平台上进行开发。
编程模型与学习曲线
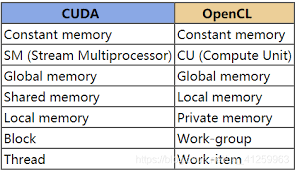
cuda和opencl在编程模型上也有所不同。cuda提供了一种相对简单且直观的编程模型,基于主机(cpu)和设备(gpu)的概念,代码分为主机代码和设备代码。开发者可以使用熟悉的c/c++语言进行编程,因此学习曲线相对平缓。
opencl则采用了一种更加通用的编程模型,代码同样分为主机代码和设备代码。但opencl使用c99语言作为基础,并引入了特定的api和内核语言来编写设备代码,这使得其学习曲线可能更陡峭一些。不过,一旦掌握了opencl的编程技巧,开发者将能够在多种硬件平台上进行高效的并行计算开发。
应用场景与兼容性
cuda主要适用于使用nvidia gpu进行高性能计算的应用,如深度学习、科学计算、图像处理等。在这些领域,cuda通常能够提供更高的性能和更好的兼容性。
而opencl则更适用于需要跨平台兼容性的应用,如在多种硬件上运行的通用计算任务。opencl的跨平台性使得它能够在不同的硬件设备上运行,从而满足更广泛的应用需求。
速度与性能对比
在速度方面,cuda通常能够在nvidia gpu上提供更高的性能。一项在nvidia gpu上直接比较cuda程序与opencl的研究表明,cuda比opencl快30%。这主要得益于cuda对nvidia gpu的深度优化和丰富的生态系统支持。
然而,需要注意的是,速度并不是衡量一个并行计算框架好坏的唯一标准。在实际应用中,开发者还需要考虑框架的易用性、可移植性、兼容性以及生态系统等多个因素。
综上所述,cuda和opencl各有其独特的优势和适用范围。cuda在nvidia gpu上能够实现极高的性能,并拥有庞大的生态系统和丰富的开发资源;而opencl则提供了一种跨平台的通用计算平台,能够支持多种处理器和设备。因此,在选择cuda还是opencl时,开发者需要根据自己的具体需求、硬件环境和开发偏好进行综合考虑。
无论选择哪个框架,掌握并行计算的基本原理和编程技巧都是至关重要的。只有这样,才能充分利用gpu的强大计算能力,提升计算效率和性能。希望本文能够帮助读者更好地理解cuda和opencl的差异,从而做出最适合自己需求的选择。











